ETL: no servers = no worries
Server-less is an approach to performing computing operations and running solutions without having to manage servers, even virtually. Those who manage tens to hundreds of servers know that this is a good dose of responsibilities, and getting rid of them is not only pleasant but also efficient. As the biggest cost item is usually the cost of administration.
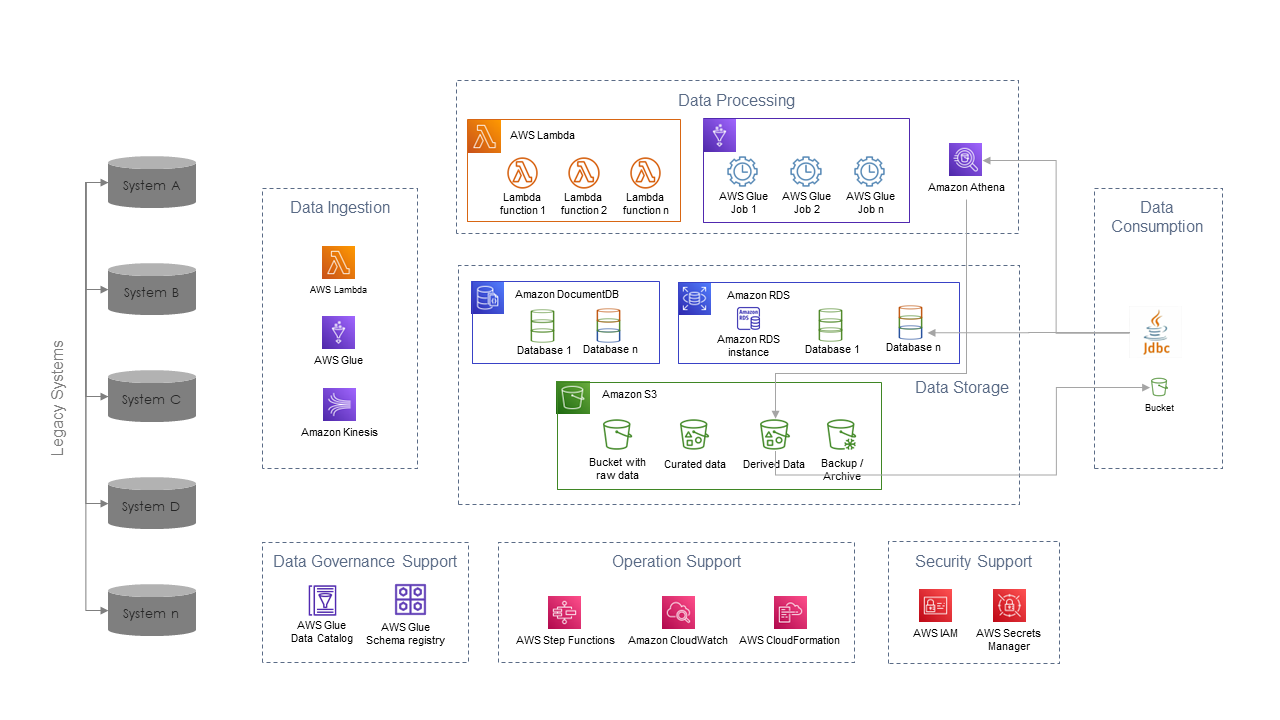
There are currently several options for implementing a serverless ETL process. We will briefly describe them using services in the AWS cloud.
AWS Glue
![]()
One of the basic services for the ETL process is AWS Glue. AWS also presents this as an ETL without infrastructure. In principle, this is an execution of Spark’s tasks implemented on a scaled AWS infrastructure. Individual tasks can be written in Python or Scala and are executed in a distributed way over data located in the S3 object repository (another service without servers). AWS Glue allows you to view data, transform it and make it available for viewing and querying via SQL.
Simply put, data (for example in CSV or Parquet) is processed into a structure and can then be accessed as a table. No matter how big it is and how many files it consists of. Other resources can be a relational database (AWS provides several of them, such as PostgreSQL or Oracle), Mongo DB, or another database accessible via the JDBC connector.
AWS Glue Catalog, a metadata catalogue, provides support for structuring semi-structured data. It is built on the Hive Meta catalogue (supports Hive DDL), and the API has the same Apache Hive Meta catalogue. It stores information about tables, columns, partitions, etc. In addition to the data catalogue, working with data is also supported by another service – the schema registry.
The processing of source data is the task of crawlers, which are tasks executed at a specified time or based on an event. Of course, individual tasks can also be planned or merged into follow-up steps and create a workflow.
AWS Lambda
![]()
An interesting option for use in the ETL process is to use the AWS Lambda service. This is a service where the individual parts of the processing are translated into the code, and the AWS Lambda service directly performs it. It is a code-execution engine where events trigger the written code. Events can come from another AWS service (eg adding a file to S3), from a scheduler, or data flow control service.
Pieces of code are in the form of functional units, which can also be packed into containers. Supported languages are Node.js, Python, Ruby, Go, Java, and C#. Of course, the code in the containers can be any. Container size is limited to 10 GB and allocated memory for each function can be up to 10 GB. Up to a thousand functions can run at one time. Code (function) run life is limited to 15 minutes. For more demanding tasks, the use of a parallel run is assumed.
AWS Batch
![]()
If 15-minutes is not enough for one task, you can use AWS Batch. This is again a service where server maintenance is not expected. In this case, however, it is not completely without servers. AWS Batch is a service where the user can run demanding batch jobs on an elastic cluster of servers or containers. Standard images of EC2 instances are used for the server running and for containers, it is the ECS Fargate service (de-facto platform for running containers as a service). There is no need to take care of servers, their administration, maintenance, etc. The batch job works in such a way that AWS Batch initiates the “creation” of a cluster of servers, on which the job runs, even for hours or days. When the job is completed, the servers or containers are “shut down” and “dropped.”
The service is useful for batch data processing, but there are practically no limitations because the limit is only whether it can run on operating systems supported by AWS, resp. in containers supported by AWS. The service is “free”. You pay just for the seconds of power used.
Amazon Athena
![]()
As part of the ETL process, it is usually necessary to access the data for querying or crawling. Amazon Athena is dedicated to these tasks. It is an interactive query “engine”, where the user accesses data through the JDBC connector and through SQL queries browses the data, or transforms, aggregates, etc.
Data stored in the form of files are stored in the S3 repository. Amazon Athena is integrated with the AWS Glue Catalog and thus acts as a table or database for the user. No matter how big the data is and how many files are actually stored. Of course, queries can also be stored and called through a scheduler (AWS Step Functions service) or based on an event or API call.
It is a serverless service, and the service itself takes care of performance and scaling. It is charged in the form of a fee for the amount of data read ($ 5 for 1 TB of data).
This service is also the primary service for access by business intelligence or reporting tools. ODBC and JDBC protocols allow connection from, for example, Qlik, Tableau, DBeaver, or other similar tools for data manipulation via SQL language.
Conclusion
In conclusion, we can state that in the AWS cloud it is possible to build complete data processing without the need for a single server or infrastructure administrator. Another advantage is that the method of charging is strictly “pay per use”, so you only pay for the power consumed, and there is no need to allocate anything. Related services such as metadata catalogue, processing planner, flow designers, etc., are free.
Author
 Miloš Molnár
Miloš Molnár
Grow2FIT BigData Consultant
Miloš has more than ten years of experience designing and implementing BigData solutions in both cloud and on-premise environments. He focuses on distributed systems, data processing and data science using Hadoop tech-stack and in the cloud (AWS, Azure). Together with the team, Miloš delivered many batch and streaming data processing applications.
He is experienced in providing solutions for enterprise clients and start-ups. He follows transparent architecture principles, as well as cost-effective and sustainable within a specific client’s environment. It is aligned with enterprise strategy and related business architecture.
The entire Grow2FIT consulting team: Our team